知行合一,止于至善
千里之行,始于足下;合抱之木,生于毫末;九层之台,起于累土Spring ApplicationContext基于XML的加载过程
本文由javacoder.cn整理,转载注明出处
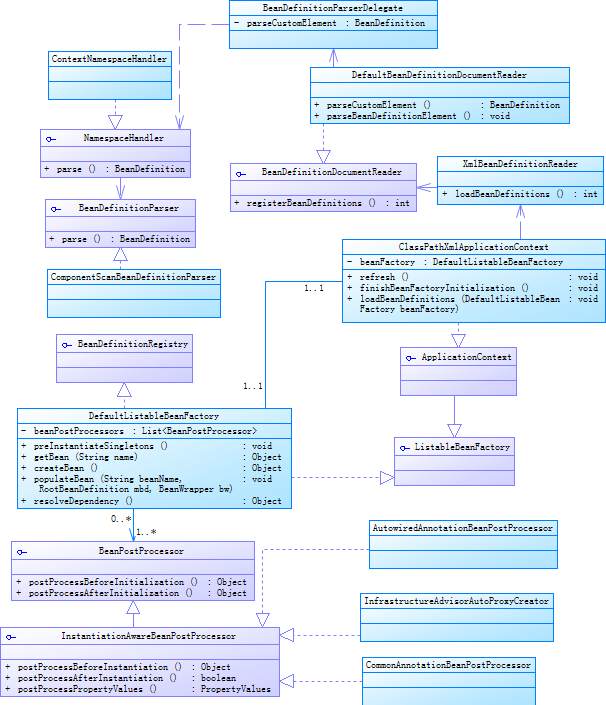
spring 将applicationContext的加载过程分为数据源的解析(生成beanDefination)和实例化(根据beanDefination生成对应的instance)两个过程, 生成beanDefination的过程因上下文的组织方式(xml 或者annotation)而异。解析xml生成beanDefination的过程由XmlBeanDefinitionReader.loadBeanDefinitions()方法完成。XmlBeanDefinitionReader类的作用是读取xml文件,校验文件的有效性,生成document对象, 然后调用BeanDefinitionDocumentReader.registerBeanDefinitions方法,BeanDefinitionDocumentReader类只解析xml的结构,比如<import>, <aliase>, <bean>, <beans>, <profile>, <resource>这些元素该如何处理。最后调用BeanDefinitionParserDelegate.parseCustomElement完成解析。 BeanDefinitionParserDelegate的主要功能有:1) 如果是默认的命名空间,那么直接生成beanDefination,2) 如果是其他的namespace查找对应的NamespaceHandler处理器。比如"http://www.springframework.org/schema/context"uri对应的处理器为ContextNamespaceHandler, 该命名空间的每个元素由对应的BeanDefinitionParser来处理。比如<context:component-scan>元素对应的parser为ComponentScanBeanDefinitionParser
最后生成bean的逻辑和基于注解的方式一致,主要就是通过AutowiredAnnotationBeanPostProcessor 处理@Autowire注解。通过InfrastructureAdvisorAutoProxyCreator生成代理, 比如处理@Transactional,。大概的类图如下(太多了,没画完,有兴趣的同学根据这个提示去单点跟踪执行):
Posted in: spring practise

Comments are closed.